PT_PERF: 基于 Intel PT 的时延性能分析工具
launched in 2024.4.25, 浙江
1 背景
1.1 常用性能分析方法
程序性能一直是开发人员和用户特别关注的指标,但其调优分析也是最为艰难的一个过程。作为系统研发人员,我们会花费大量时间来分析系统的性能瓶颈、定位开发过程中引入的性能回退,并解决可能周期性发生的性能抖动问题。
根据线程的执行模型,即是否调度在 CPU 上执行指令,我们通常会从 on-CPU 和 off-CPU 两个角度进行分析[1]。在 on-CPU 分析中,我们关注那些正在 CPU 上执行指令的线程,以识别 CPU 指令执行的热点。而 off-CPU 分析则关注那些不在 CPU 上执行指令的时间,比如等待磁盘 I/O、锁或网络传输等资源。
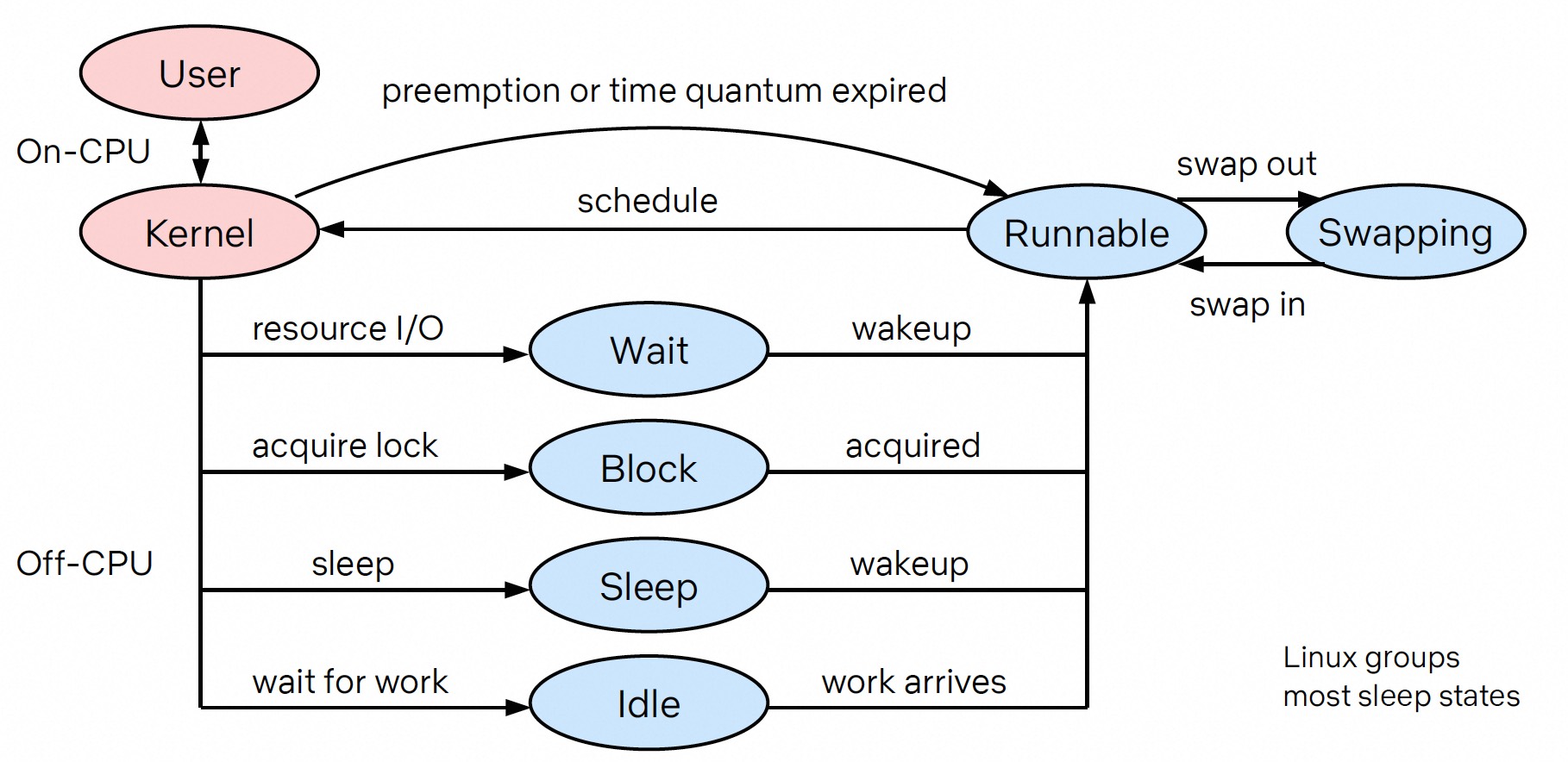
CPU 是负责执行指令的核心部件。我们可以使用 perf 工具对 CPU 上执行的指令进行采样,通过 perf report 或者创建 on-CPU 的火焰图,从而了解大部分 CPU 执行的指令时间主要集中在哪些函数上。这些采样数据主要基于性能监控计数器(PMC)提供的硬件溢出中断(PMI),通过这种方式,CPU 周期性地向内核传递当前指令的位置(ip)。内核利用当前线程的栈帧或者程序的 dwarf 信息来构建函数调用栈。通过在一定频率下的采样,尤其是在 CPU 密集型负载下,我们可以确定大部分的性能瓶颈所在。
然而,在非 CPU 密集型的场景下,比如大量 IO 操作、等待锁或主动休眠等情况,CPU 利用率很低。在数据库场景中,这种情况非常常见,CPU 上的热点并不一定与性能瓶颈直接相关。可能大多数线程因为等待某个 mutex(互斥锁)而被调度出去。这时我们更多需要关注 off-CPU 上的瓶颈,可以通过如 pstack 打栈,将每个线程的瞬时函数调用栈打印并聚合起来,或者基于 ebpf 的 off-CPU 火焰图(通过记录线程 schedule 出去到回来的时间)来分析。当线程足够多,并且线程等待时间足够长,我们能判断出线程卡在何处。但找到谁卡住大部分线程是件比较困难的事,因为这可能只是一个短暂持有锁周期性的 on-CPU 任务,并且依赖于一定的代码经验。
在开发引入性能回退时,我们经常需要对比两套代码的开销差异,这个开销区别可能只是两个函数是否是内联的,精确到时间也只是数十纳秒的区别,因为调用频次高而引入了性能回退。在此之前我们最为习惯的是在编译前对程序埋点,但这费时费力,依赖于一定代码经验,并且修改代码也影响了程序的执行行为。我们也可以利用 uprobe 技术在程序运行时动态埋点,统计指定函数的时延,但内部统计过通常 uprobe 使能开销就是 2000 cpu cycles,并且在高频函数调用下,对程序性能的影响达到 50% 以上。
另一个令人头疼的问题是性能抖动排查,即程序在周期性地出现性能急剧下降,下降时间很短。例如,IO 延迟抖动等情况。我们使用的工具大多是基于平均值的统计方法,难以捕捉到短暂的程序状态。我们通常凭借代码经验,在代码中插入陷阱并打印日志来发现问题。
为了解决这些问题,我们希望能够在指令级别还原程序的执行过程,同时不对程序的正常执行过程产生影响。为了实现这一点,这依赖于硬件提供的程序 trace 功能。
1.2 Intel Processor Trace
Intel 在 Broadwell 之后的 CPU 架构引入了 Processor Trace 技术,通过专门的硬件,以较小的性能损失记录程序控制流信息,并将其编码压缩成一系列的 packet 流,packet 的内容包括:
- 程序控制流信息,记录了每次的 branch 跳转。
- 统计信息,如指令执行时的时间戳。
基于连续的 packet 流,有了 branch 跳转信息,用户层再进行 decode,就能复原出当时程序的执行流。对于使用者而言,无需修改源代码重新编译,只需要在程序运行时,使能 PT trace,此时 packet 开始产生。trace 流在发送至内存之前,首先会在缓存在内部的硬件 buffer 中。和 LBR (Last Branch Record)类似,Intel PT 主要原理也是记录 branch 跳转,但相比之下,能够追踪更长的 branch 记录。基于 branch 跳转,就能复原当时的程序指令执行过程。
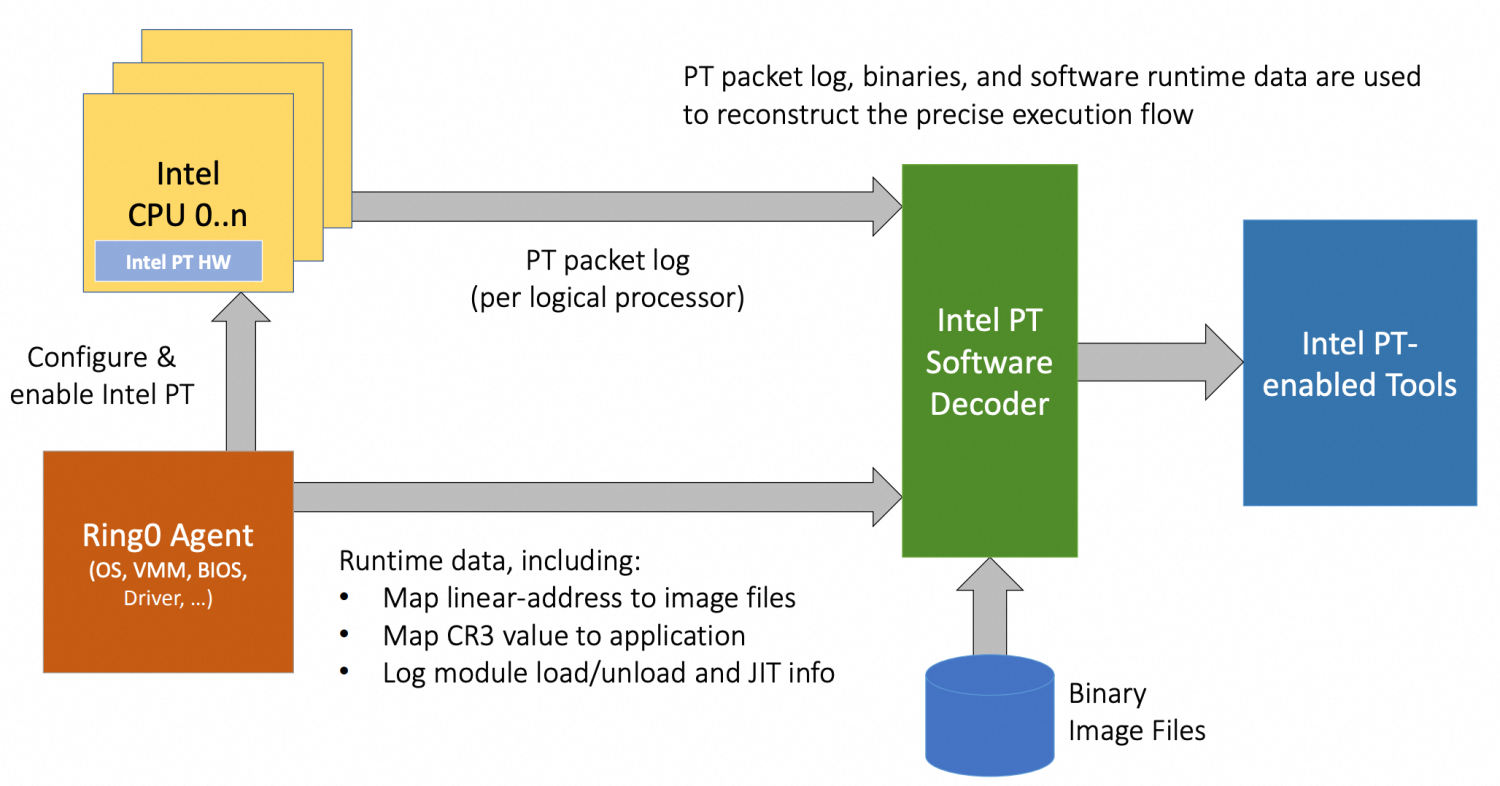
2 PT_PERF 时延分析工具
基于 Intel PT 的程序 trace 技术,我们实现了 PT_PERF 的时延分析工具,使用 PT 的 trace 数据来显示程序执行的关键信息如函数时延,时延曲线,时延火焰图等信息。整个流程实现基于 Linux perf tool,包括 perf record、perf script 以及结果汇总输出阶段。
指定采集一段时间后,PT_PERF 支持:
1.函数分析
- 统计目标函数的时延分布直方图,平均时延。
- 统计目标函数的子函数调用时延。
- 统计按上层函数分组统计目标函数的时延分布。
- 分别统计目标函数的 On-CPU 和 Off-CPU (Schedule) 统计 (需要 root 权限)。
2.timeline 时间线分析
- 按线程给出函数关于 trace 时间的时延曲线图。
- 统计函数在某一时间范围的 trace 数据,进行分析。
- 查看某个时间点的函数栈 pstack。
3.Flamegraph 火焰图分析
- 基于函数时延的火焰图:使用 pt_flame 进行分析。
- on-cpu 的火焰图:和传统基于硬件溢出中断模式的采样类似。
4.历史分析
- 先 trace 某段时间全量数据,再进行分析。
2.1 使用
2.1.1 安装
PT_PERF 已经开源至 github。在 Linux 4.2+ 和 GCC 7+ 版本下,可以通过下面命令安装
sudo yum install binutils binutils-devel elfutils-libelf-devel -y
git clone https://github.com/mysqlperformance/pt_perf.git
cd pt_perf
make
为了输出时延火焰图,PT_PERF 依赖于 pt_flame 来支持输出时延火焰图,可以通过下面命令安装
git clone https://github.com/mysqlperformance/pt-flame.git
mkdir build && cd build
cmake -DCMAKE_INSTALL_PREFIX=/usr/share/pt_flame -DCMAKE_BUILD_TYPE=RelWidhtDebInfo ../
cmake --build .
cmake --install .
在使用之前我们需要配置一些系统参数,修改 perf_event_mlock_kb 支持更大的 trace buffer,减少 trace 数据丢失。
修改 kptr_restrict 支持追踪内核函数,如追踪 off-cpu 分析需要的 schedule 内核函数。
echo 131072 > /proc/sys/kernel/perf_event_mlock_kb
echo -1 > /proc/sys/kernel/perf_event_paranoid
echo 0 > /proc/sys/kernel/kptr_restrict
下面我们以几个场景来看如何使用 pt_perf。
2.1.2 场景一:函数分析
我们在 Intel(R) Xeon(R) Platinum 8163 机器的 24 core 上启动了一个 MySQL 8.0 程序,并启动了 Sysbench 的 oltp_read_only 128 线程负载去压测 mysql。我们在 16s 时启动 pt trace,此时性能有轻微的下降 (约 3%)。
[ 14s ] thds: 128 qps: 229687.19
[ 15s ] thds: 128 qps: 229213.65
[ 16s ] thds: 128 qps: 226838.86 # start trace
[ 17s ] thds: 128 qps: 224836.49
[ 18s ] thds: 128 qps: 221274.61
[ 19s ] thds: 128 qps: 223444.64
使用下面的命令 trace 1 秒后,对 mysql 的 do_command 函数(接受并执行 SQL 的入口函数)进行分析,
$ sudo ./func_latency -b "bin/mysqld" -f "do_command" -d 1 -p 60416 -s -i -t -o
通过 -b 指定二进制文件,-f 指定分析的函数名称,-p 指定 mysqld 的进程,-s 使用并行的 perf script 来加速 trace 数据的解析,-o 输出函数的 off-cpu 信息。
通过 -i 使用 PT 的地址过滤,即在 trace 阶段只记录 do_command 的函数进入和跳转,极大减少了 trace 的数据量,不过需要在 Linux 5.10+ 版本才支持,不使用地址过滤的话,会 trace 所有函数的跳转,在 perf script 阶段将其他函数调用的 trace 丢弃。
通过 -t 使用 per-thread 的模式进行采样(per-thread 模式默认每个 thread 一个 trace buffer,采样性能影响小,线程数多会使用更多的内存消耗)。
最后 pt_perf 会输出 do_command 的函数分析结果:
Histogram - Latency of [do_command]:
ns : cnt distribution sched distribution
16384 -> 32767 : 132 | | 150 | |
32768 -> 65535 : 8487 |*** | 16063 |****** |
65536 -> 131071 : 22384 |******* | 27139 |********** |
131072 -> 262143 : 39483 |************** | 33818 |************ |
262144 -> 524287 : 56138 |********************| 52723 |********************|
524288 -> 1048575 : 44559 |*************** | 39089 |************** |
1048576 -> 2097151 : 35373 |************ | 28610 |********** |
2097152 -> 4194303 : 4663 |* | 2167 | |
4194304 -> 8388607 : 23 | | 12 | |
8388608 -> 16777215 : 2 | | 2 | |
trace count: 211244, average latency: 610493 ns
sched count: 199813, sched latency: 503275 ns, cpu percent: 2264 %
sched total: 205337, sched each time: 517752 ns
============================================================================================================
Histogram - Child functions's Latency of [do_command]:
name : avg cnt sched_time cpu_pct(%) distribution (total)
Protocol_classic::get_command : 502643 211244 495234 156.51 |********************|
asm_sysvec_call_function_single : 192055 7 189609 0.00 | |
dispatch_command : 107245 211347 8025 2096.98 |**** |
asm_sysvec_apic_timer_interrupt : 50563 35 43869 0.02 | |
__irqentry_text_start : 14598 195 3143 0.22 | |
vio_description : 338 211347 5 7.03 | |
my_net_set_read_timeout : 40 422591 1 1.64 | |
Diagnostics_area::reset_diagnostics_area : 23 211244 1 0.46 | |
Protocol_classic::get_output_packet : 10 422719 0 0.44 | |
Protocol_classic::get_net : 7 211244 0 0.15 | |
结果比较多,主要包括:
- 首先是 do_command 的时延分布直方图,如时延在 131072 ns 到 262143 ns 区间的调用次数为 39483 次。
- 以及 do_command 的汇总,‘trace count’ 指出了在 trace 期间 do_command 一共调用了 211244 次,平均时延为 610493 ns,这和 sysbench 的 QPS 是接近的,其中调用期间线程被调度了 199813 次,平均 off-cpu 时延为 503275 ns,cpu 比例为 2264%,这和 top 看到的是类似的,do_command 开销大约用了 22~23 个 core。
- 接下来是 do_command 每个子函数调用的平均时延,调用次数,被调度出去的时间,cpu 比例,以及总的时延分布。可以看到 do_command 大部分被调度出去都是在等待客户端发包 (get_command),大部分 cpu 时间都花在执行 SQL 上 (dispatch_command)。
我们也可以通过 --li/--latency_interval=131072,262143 来看时延在131072 ns 到 262143 ns 区间的函数主要开销在哪里。
2.1.3 场景二:火焰图
火焰图是一种将函数调用栈可视化的方法,使得能够从复杂的函数调用关系中展示出程序的热点。
使用下面的命令 trace 1 秒后,会调用 pt_flame 将所有的函数调用解析,得到以时延为统计基础的火焰图,pt_flame 是我们开发用于解析函数跳转得到时延火焰图的工具,感兴趣的读者可以阅读其实现。
./func_latency --flamegraph="latency" -d 1 -p 60416 -t -s
时延火焰图给出了每个函数的调用次数,平均时延,以及来自哪个函数调用栈。通过时延火焰图,我们能很容易看到时延花在哪个调用栈以及哪个函数上,如下面火焰图,我们可以看到大部分时延都在读 IO 上,并且能看到占比多少。由于使用了全量 trace 数据,在高负载下需要减少 trace 时间,来避免过大的内存和磁盘空间占用,以及更长的解析时间。
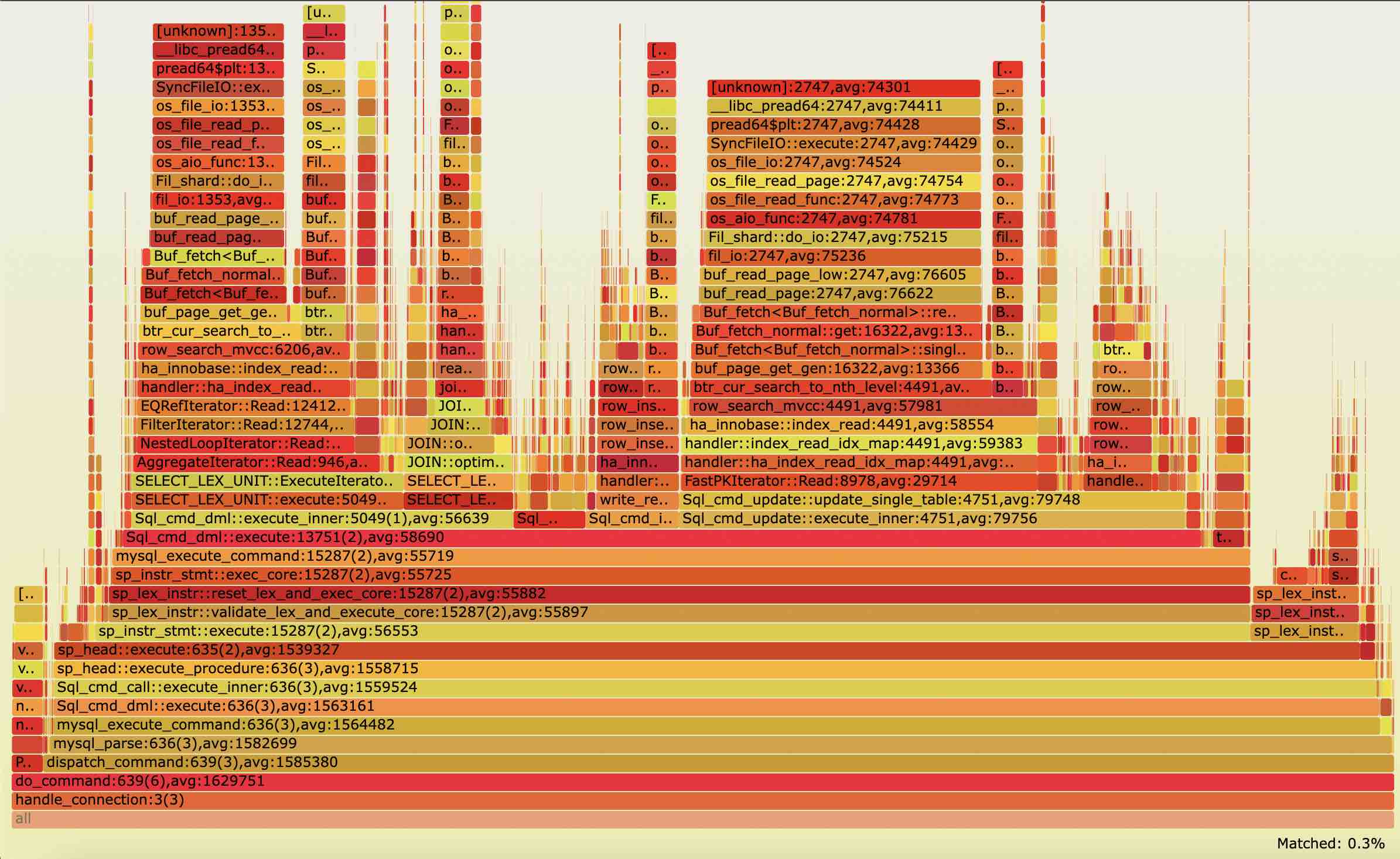
使用下面的 trace 命令,我们还能得到 on-cpu 的火焰图,将 PT trace 的指令,目前设定每个 10us 输出一次调用栈,得到和 PMI 类似的 on-cpu 的火焰图,即火焰图给出的是函数的采样次数显示的火焰图,但采样间隔较短,输出 cpu 火焰图会更精确,但时间也更久。
./func_latency --flamegraph="cpu" -d 1 -p 60416 -t -s
2.1.4 场景三:时间线分析
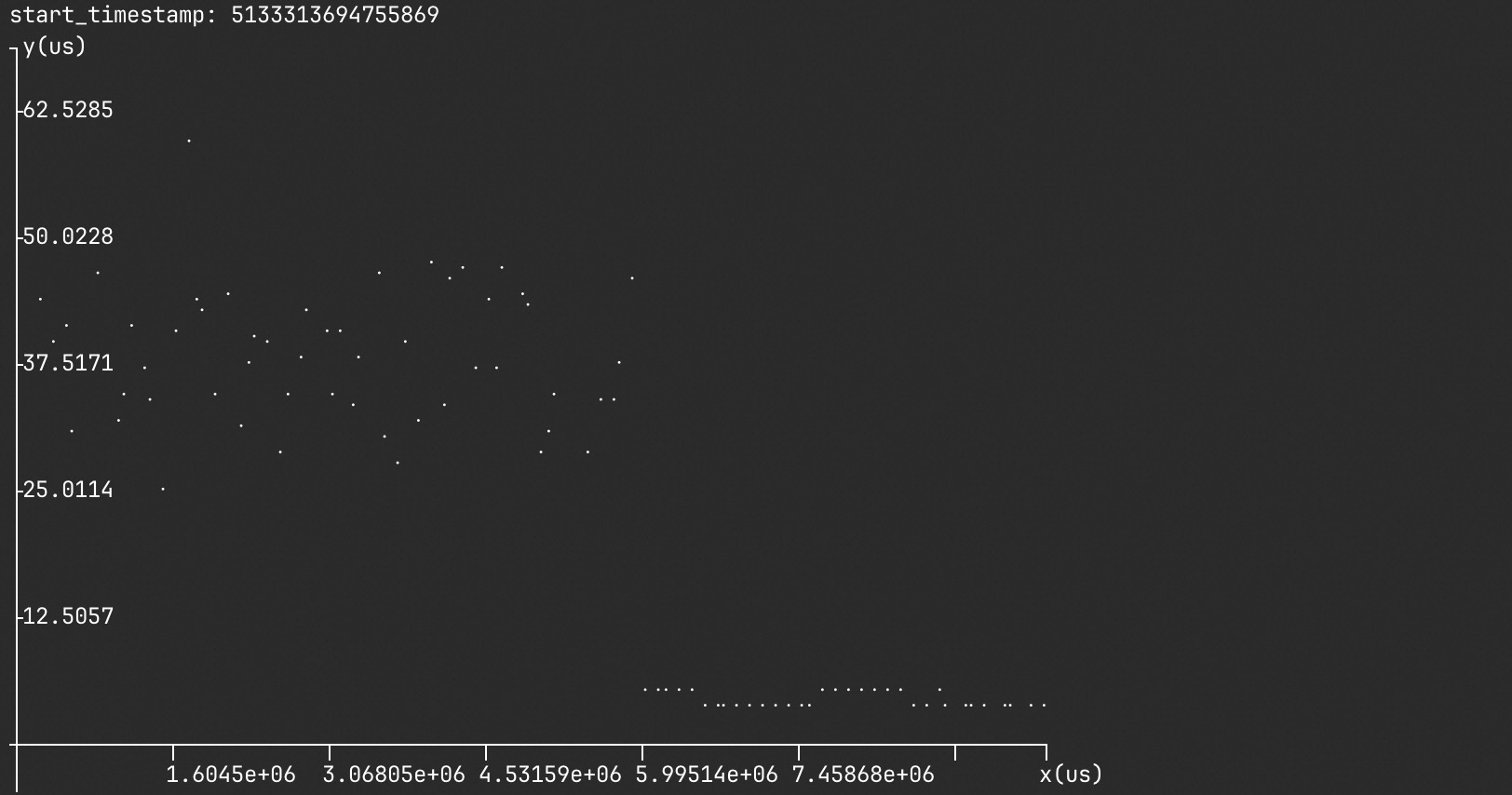
当系统状态发生波动,我们需要观测程序时延的波动曲线,来对比波动前后的差异。举个例子我们启动 oltp_insert 负载,并在 5 s 切换了 redo 落盘策略(从事务需要等待日志落盘,到不需要等待落盘)。
我们通过 -l/--timeline 来指定查看函数 trx_commit 在 trace 期间的时延散点图,通过 -T / --tid 指定查看的线程 id 为 123173。默认每个时延打一个点,也可以通过 --tu/timeline_unit 来指定每 100 个时延求平均画一个点。
./func_latency -b bin/mysqld -f "trx_commit" -d 10 -t -s -l --tu=100 -T 123173
图中在 5 s 的时候做过一次落盘切换,trx_commit 时间发生改变,从平均 35us 下降到了 7us 左右。
也可以通过 -ti=start,min,max 缩小时间范围查看,start 指定起始的时间戳,如图中的 start_timestamp。min,max 指定查看的距离 start 的区间,单位是纳秒。这样也能查看指定时间范围后的函数分析结果以及火焰图,来确认这段时间函数时延为什么降低,或者为什么抖动。
2.1.5 场景四:历史分析
虽然 trace 阶段不影响运行程序,由于程序 trace 的数据量比较大,分析时为了更快获得结果,会占用不少 cpu 资源。此时我们可以将 trace 数据转移到另一台机器上去解析得到分析结果。避免影响 trace 的程序。
我们可以使用 --history=1 来 trace 全量数据,其实就是保存了 trace 的源文件 ‘perf.data’,将 perf.data 和 trace 程序的二进制文件复制到另一台机器。注意 trace 程序的二进制所在目录路径需要和原机器一致。
# 按 pid 采样
./func_latency -d 10 -p 60416 -t --history=1
# 按 tid 采样
./func_latency -d 10 -T 123173 -t --history=1
# 按 cpu 采样
./func_latency -d 10 -C 0-47 --history=1
在另一台机器使用 --history=2 来输出分析信息。
./func_latency -b bin/mysqld -f "trx_commit" -d 10 -t -s -l --tu=100 -T 123173 --history=2
2.2 实现过程
Linux 在 4.1 版本之后的 perf tools 开始支持了 Intel PT。
通过 perf record 命令,我们能很容易地使能 PT trace,得到原始的 PT packet 数据,并通过 perf script 进行解析得到可读的执行信息,如通过 --itrace=cr 输出了下面的 call-return 调用关系结果。包含了 线程 ID,CPU ID,时间戳,跳转指令,函数 IP,symbol 等。
perf record -e intel_pt/cyc=1/u
perf script --itrace=cr

PT 的 perf script 是非常耗时的,并且解析结果的数据量也很大。举个例子,Intel Core i5-8259U 机器上,对于运行 7 毫秒的工作负载,PT trace 数据量大约 1MB。perf script 大约需要 20 秒[4],得到 1.3 GB 的解析结果。
因此为了加速 trace 和解析速度,我们修改了 Linux perf tool,使得支持并行 script 以及解析过滤。
基于用户态的 Linux perf tool,整个 PT_PERF 包括三部分:perf record,parallel script 以及 analyze 过程。
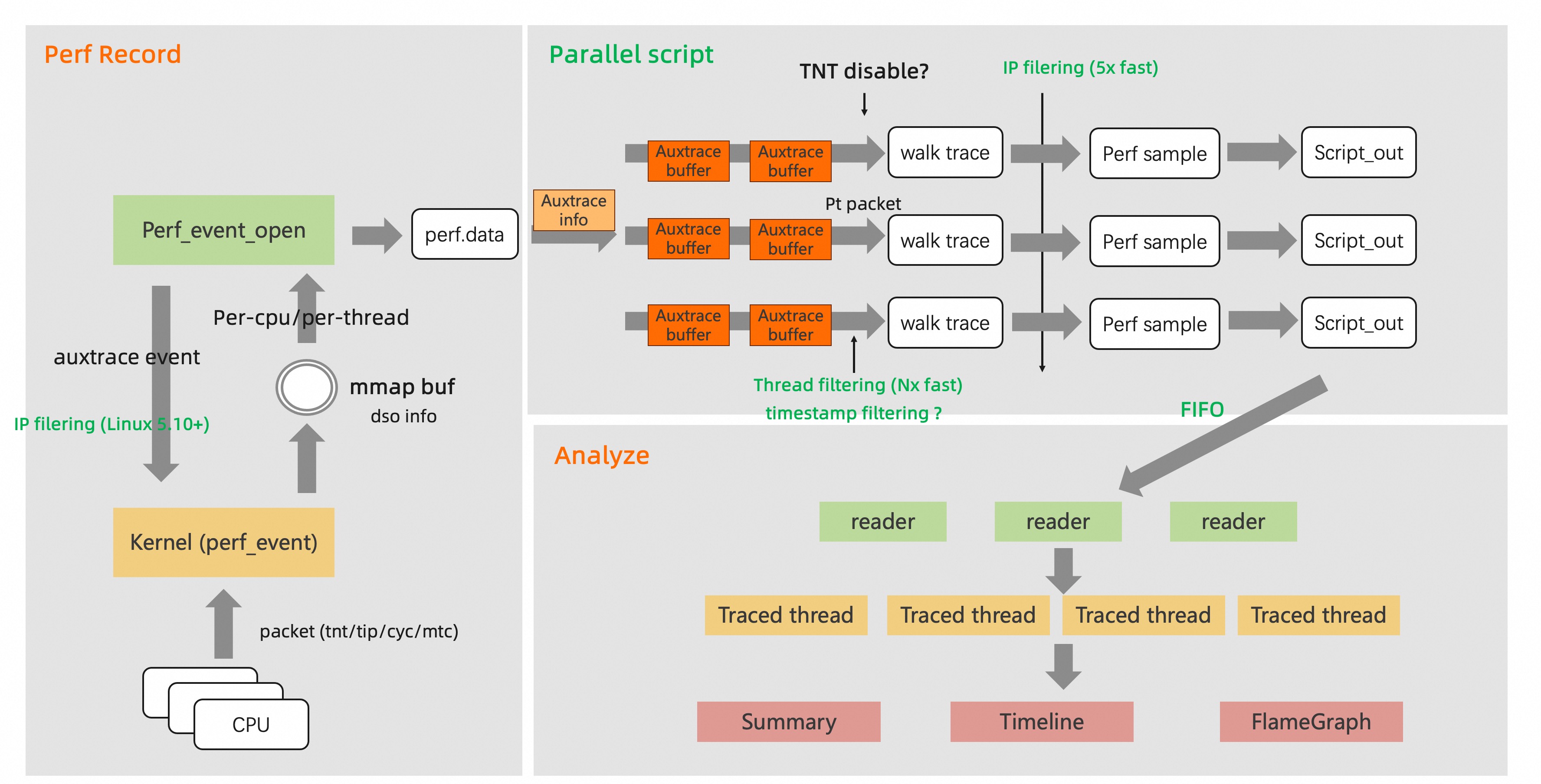
2.2.1 perf record 阶段
这一步主要是使能 PT trace,通过 perf_event_open 系统调用来操作内核的 perf event 子系统。对于 perf 来说,所有的硬件 trace 流都是基于 auxtrace event 来实现的。
Intel PT 使用 Aux area 来记录所有的 packet 流,使用单独的 mmap buffer。当 Aux buffer 满之后,会生成一个 PERF_RECORD_AUXTRACE event,在其之后会存有实际的 PT trace 数据。每生成一个 PERF_RECORD_AUXTRACE,会在 perf.data header 的 auxtrace_index 增加一块 aux buffer 索引,用于后续 script 时,将所有 aux buffer 加入 pt_decoder 解码器的 buffer queue 中。除此之外,还会有一个 PERF_RECORD_AUXTRACE_INFO 来记录一些元信息,如标识当前 auxtrace 是 Intel PT 的 trace,以及相应的硬件架构信息。
perf record 采样模式分为 per-cpu 和 per-thread 两种。per-cpu 采样默认每个 CPU 一个 Aux buffer,per-thread 则是每个线程一个 Aux buffer。per-thread 因为本身 buffer 是以线程组织的,在多核下不需要记录和解析大量的线程 switch 事件,对性能和解析速度影响低,但线程多时需要消耗更多内存,并且依赖 pid 模式,需要每个 thread 对每个 cpu 开启一次 perf_event_open。
PT 的 trace 数据只是一系列指令流,不带线程,CPU 信息以及程序符号信息。因此除了得到带有 PT packet 数据的 Auxtrace event,perf record 还会采集用于辅助解析 pt trace 的事件。
- PERF_RECORD_COMM event:记录了进程 pid/tid 和线程名等信息。
- PERF_RECORD_MMAP2 event:记录了进程的内存信息,后续用于从二进制中从指令中解析符号,以及还原指令流时获取下一条指令。
- PERF_RECORD_SWITCH event:在 per-cpu 模式下,记录了 CPU 上的线程切换,用于解析某个时间戳下,当前 CPU 上的执行线程 ID。
PT 可以在每个 CPU 每秒产生 100MB 的 trace 数据。这可能比记录到文件的速度要快 (导致跟踪数据丢失),有时甚至比记录到内存的速度还要快 (导致数据包溢出)。 因此在 record 阶段使用 IP_filtering 能减少数据 trace 量,也减少了丢失的概率。不过 Linux 5.10+ 版本才支持对进程内所有线程应用 ip_filtering。
2.2.2 parallel script 阶段
这一步主要是将 perf record 得到的 PT packet 解析得到可读的函数跳转。相当于用 PT 的 packet 流复刻了 trace 阶段程序的指令执行过程。这也是最为耗时和占用资源的过程,原先的 perf script 是单线程的。为了加速 script 过程,我们将 script 的解析并行化。
正常解析流程时,当解析到 PERF_RECORD_AUXTRACE_INFO event 时,perf 会将 auxtrace_index 中所有的 aux buffer 加入到 intel_pt_queue 中,对于 per-cpu 模式,queue 按照 cpu 组织,对于 per-thread 模式,queue 按照 thread 组织。PT_decoder 解码器会从 intel_pt_queue 不断拿出 aux buffer,并从 aux buffer 拿出连续的 packet 块(PSB),每个 PSB 不相互依赖,都带有当前程序所在的 IP,这样在丢失 trace 数据时,还能从新的 PSB 中还原后续的指令执行。
拿到 aux buffer 后,PT_decoder 进入 walk trace 阶段,从当前指令 IP 出发,获取程序的符号表不断获取下一条指令 IP,直到遇到 branch 跳转,这时会从 aux buffer 获取一个 packet ,根据 packet 的内容来判断跳转的下一个 IP 是哪里。同时会生成一个 perf sample,perf sample 是 perf script 的标准输出,如指定 --itrace=cr 情况下,perf sample 会输出一条前面展示的函数跳转,此时在提交 perf sample 时,我们还能增加过滤条件来减少输出,提升后续解析速度,如 IP 过滤,thread 过滤,时间过滤等等。
由于 auxtrace_index 在 perf record 阶段对于线程或者 CPU 而言就是按照时间顺序增加,并且对于 PT_decoder,intel_pt_queue 有多少连续的 aux buffer,就能输出这个连续 buffer 区间的 perf sample。
因此为了实现并行的 script,在加入 intel_pt_queue 阶段时,我们将所有 aux buffer 进行划分,每次 forker 出一个子进程来处理部分的 aux buffer,加入到各自的 intel_pt_queue 中进行 walk_trace。
为了保证没有 PSB 丢失,每个子进程需要将各自所有 aux buffer 涉及的每个 cpu 或 thread (取决于 per-cpu 还是 per-thread 模式)最后一个 aux buffer 的 PSB 补齐。
2.2.3 analyze 阶段
在这个阶段,数据已经是可读了,perf script 的结果已经包含了所有线程的函数跳转信息。
我们只需并行读入 perf script 的结果,按每个被 trace 的 thread 划分,用每个 traced thread 去计算函数时延,计算函数调用栈和各自的时延曲线。最后进行汇总输出函数分析结果,火焰图等。
通过对内核 schedule 函数的 trace,我们也能够清楚知道程序 on-cpu 和 off-cpu 的占比。
引用
[1] Extended BPF A New Type of Software, Brendan Gregg
[2] 内核 perf 框架解构系列:PMU 硬件架构相关的概念及编程
[3] Perf tools support for Intel® Processor Trace
[4] Enhance performance analysis with Intel Processor Trace.