从编译器视角看 MySQL 的查询引擎
launched in 2023.10.15, 浙江
最近一直想了解 MySQL SQL Engine 的大概实现,写些文章主要简单总结一下最近的学习内容。
内容分为两个部分:先介绍编译器和 MySQL SQL engine 的一些概念,使得对 SQL engine 的一些术语有些大概的了解。
第二部分结合 mysql 代码来看 SQL engine,具体来看 MySQL 的 SQL 查询执行流程。
文章大部分内容基于 Norwegian University of Science and Technology 的一篇论文 “Compiling expressions in MySQL“ 和 “Understanding MySQL internals” 这本书,以及 MySQL 8.0 源码,感兴趣的可以阅读一下原文。
1 编译和编译器
在计算机中,编译是一个通用术语,它描述了一个过程,该过程接受某种语言输入 (通常是编程语言) 并产生另一种语言的输出 (通常是机器码)。编译器是使用编译来产生一些可执行输出的程序。
编译器的一个例子是 GCC 或Clang (LLVM 的 C 前端)。编译器通常可以分为三个部分: 前端,优化器和后端。
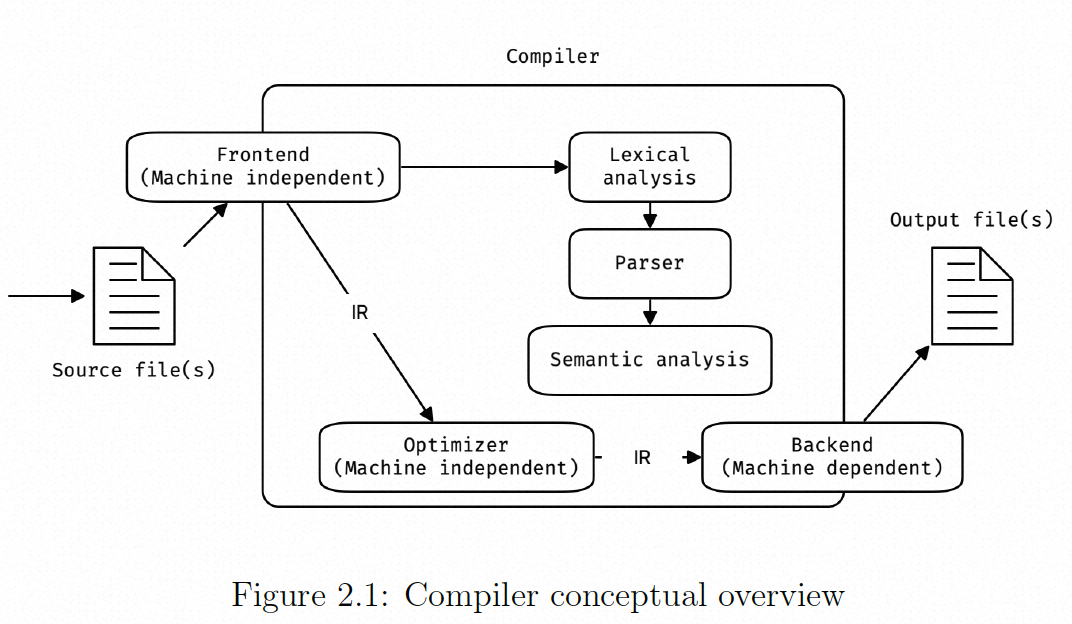
前端:负责面向源语言,并将其转换为可在编译器内部使用的中间表示 (IR)。前端通过首先运行词法分析(也称为 scanner) ,依次输出 token 流。token 是简单的字符集合和字符对应的类型,例如 “+=” 的类型是 “操作符”。然后将 token 流传递给 parser。parser 将 token 流转换为抽象语法树 (AST)。同时,对 token 流进行推理并确保它是有意义的。语义分析器 (semantic analyzer)负责确保输入语法上有意义。通常会有几个符号表 ,每个符号表对应一个作用域,可能是全局作用域、函数作用域或任何其他作用域。
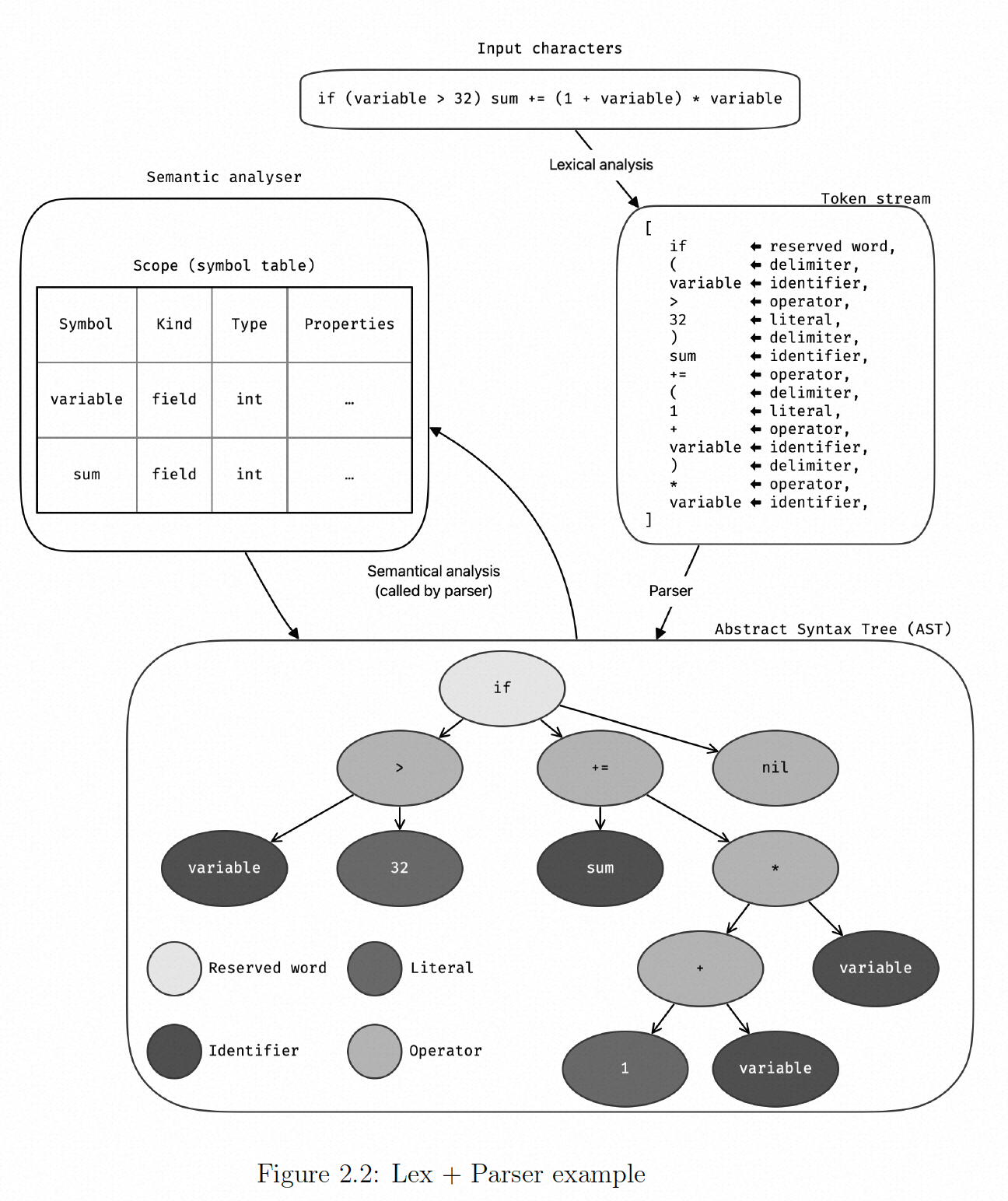
图 2.2 是个前端解析的例子,经过词法分析得到 symbol 的符号表,通过 parser 和语法分析生成 AST。 AST 是一种树状结构,如图中的最下面这张图,其中包含关于每个 token 的一系列信息,并将其逻辑地放置以用于创建 IR。例如, AST 中的操作符将包含有关其操作数及其类型的信息,以便语义分析可以推断类型并确保可以创建结果。AST 还包含有关每个 token 在源代码中的位置的信息。这些信息有助于编译器报告潜在错误的位置。
优化器:在前端之后,将 IR 做提前转化和优化,典型优化如:loop optimization, dead code elimination ,global value numbering。IR 通常比源语言更接近机器码,但保留与源语言相同的机器独立性。优化器在优化 IR 时不需要考虑硬件问题,并且可以将所有依赖于机器的函数留给编译器的后端部分。在转换和优化结束时, 优化器本身将输出 IR 的改进版本,表示与给出的 IR 相同的源代码。
后端:从优化器获取 IR 的改进版本,并将其转换为可执行的与机器相关的机器代码。后端依赖于机器的原因是它必须考虑各种体系结构。后端一个较为重要的操作:寄存器分配,它将各种值和变量分配给 CPU 中有限数量的寄存器。寄存器分配实现更好的运行时性能。
2 数据库的相似之处
数据库的行为很像编译器,通过将 SQL 语句,解析并创建出以查询计划的形式的逻辑运算。
parsing 对应于编译器的前端,执行语法语义分析,转换为 parse tree 形式的 IR。parse tree 与 AST 的不同之处在于它表示整个输入,并且不考虑语言语法。如,对于输入 (x+2),解析树将包含所有 token,包括括号。AST 将省略括号,因为它将生成一个 '+' 节点,' x ' 和 ' 2 ' 作为子节点。
DBMS 通常会在 parse tree 上应用转换和优化,最终转换为逻辑执行计划,逻辑查询计划描述了查询的可能逻辑计算流。最后,优化器将逻辑执行计划转换为物理执行计划,该物理查询计划由执行器执行。DBMS的执行器可以看作是一个解释器 ,它接受物理查询计划并逐条记录执行它,这里的 parse tree,逻辑执行计划和物理执行计划会在后面具体介绍在 MySQL 的形式。
3 从 SQL 语句到结果的过程
任何关系数据库在从查询到结果时都将经历类似的步骤:parse, prepare, optimize 和 execute。从编译器的视角来看,parse 和 prepare 阶段可以看作同一个阶段,数据库中还会解析对应表中的 fields,类似编译器的语法分析。
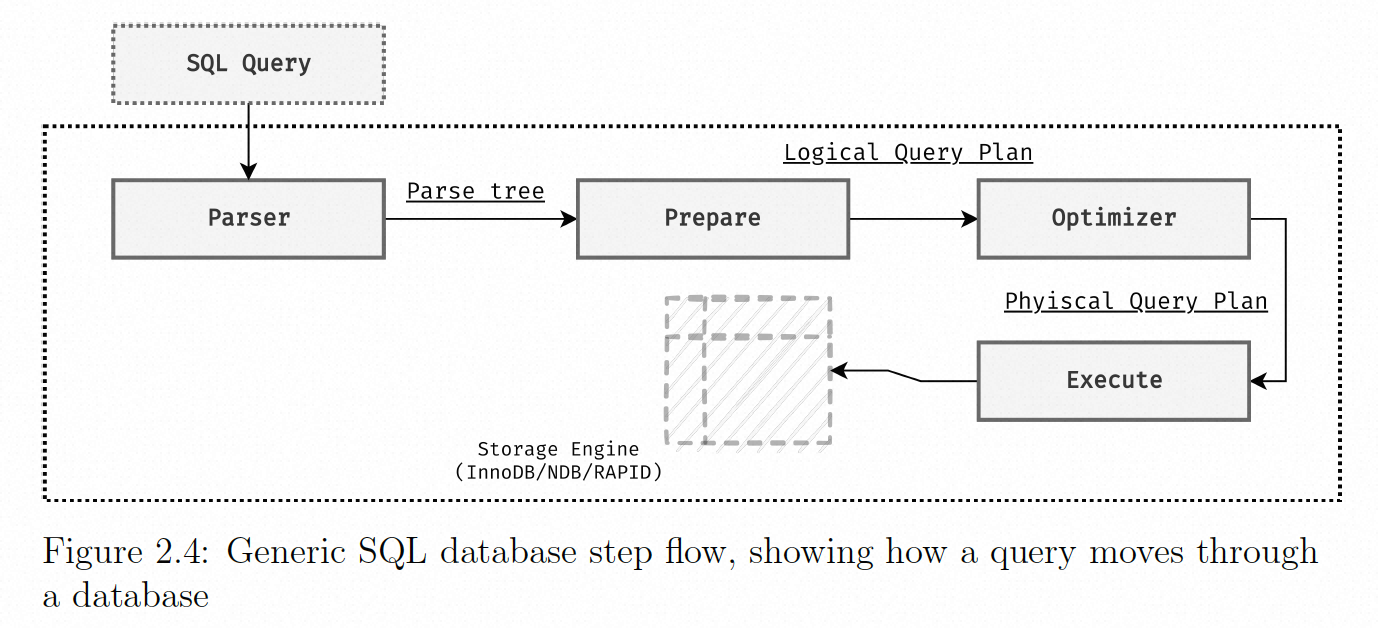
当向数据库发送查询时,数据库运行 的第一步是 parse。parse 是数据库将明文的 SQL 查询语句转换为可操作的内容的第一步。这一步的结果是一个内部树状 C++ 结构 ,表示查询的各个部分。进行语法和词法解析。
下一阶段 prepare,此时,数据库会解析 fields,确保查询是可执行的。解析 fields 涉及到从表的各个字段信息中做出类型推断。还将树结构中的字段节点绑定到具有相应类型的实际行引用,解析的另一个结果是,如果查询中引用的特定字段实际上不在对应的表中,并且无法解析,向前台报错。 当将查询的必要的 fields 解析后,数据库会进行优化,使得查询执行更加高效,如常量折叠(直接进行常量运算)和无用代码消除。此时得到逻辑查询计划。
下一步是 optimize 阶段,根据前面的 prepare 后的 parse tree 的逻辑查询计划,得到具体的 物理执行计划 。生成的物理查询计划将描述执行器应该如何连接哪些表以使执行尽可能快速和有效 。找出哪些连接组合的过程可能是穷举的,但是当连接的数量增加时,穷举搜索很快就变得不可行了。
最后,数据库将通过 execute 步骤执行物理查询计划。然后,该步骤将读取存储引擎,以获取物理查询计划可以使用的行数据。
4 Volcano query evaluation system (火山查询执行模型)
Volcano 是一个标准的迭代器 SQL 执行模型。
1994 年由 Graefe 引入的 Volcano 查询引擎系统已经成为 关系数据库中的标准。该模型将查询表示为关系代数算子树。算子包括:join,selection,projection 以及其他特殊领域专用的算子。
Volcano 中的另一个重要概念是迭代器接口。迭代器接口强制每个算子实现以下函数: open()、next() 和close();
Volcano 执行查询的方式是通过算子树的根节点在其子节点上调用 next()。这反过来意味着,直到叶节点也将在其算子上调用 next()。叶节点执行 next(),通常 执行一行数据的实际读取,然后数据将通过各种操作符向上冒泡聚集,直到到达根节点。
形成算子执行的 pipeline:从上往下的控制流和从下往上的数据流。
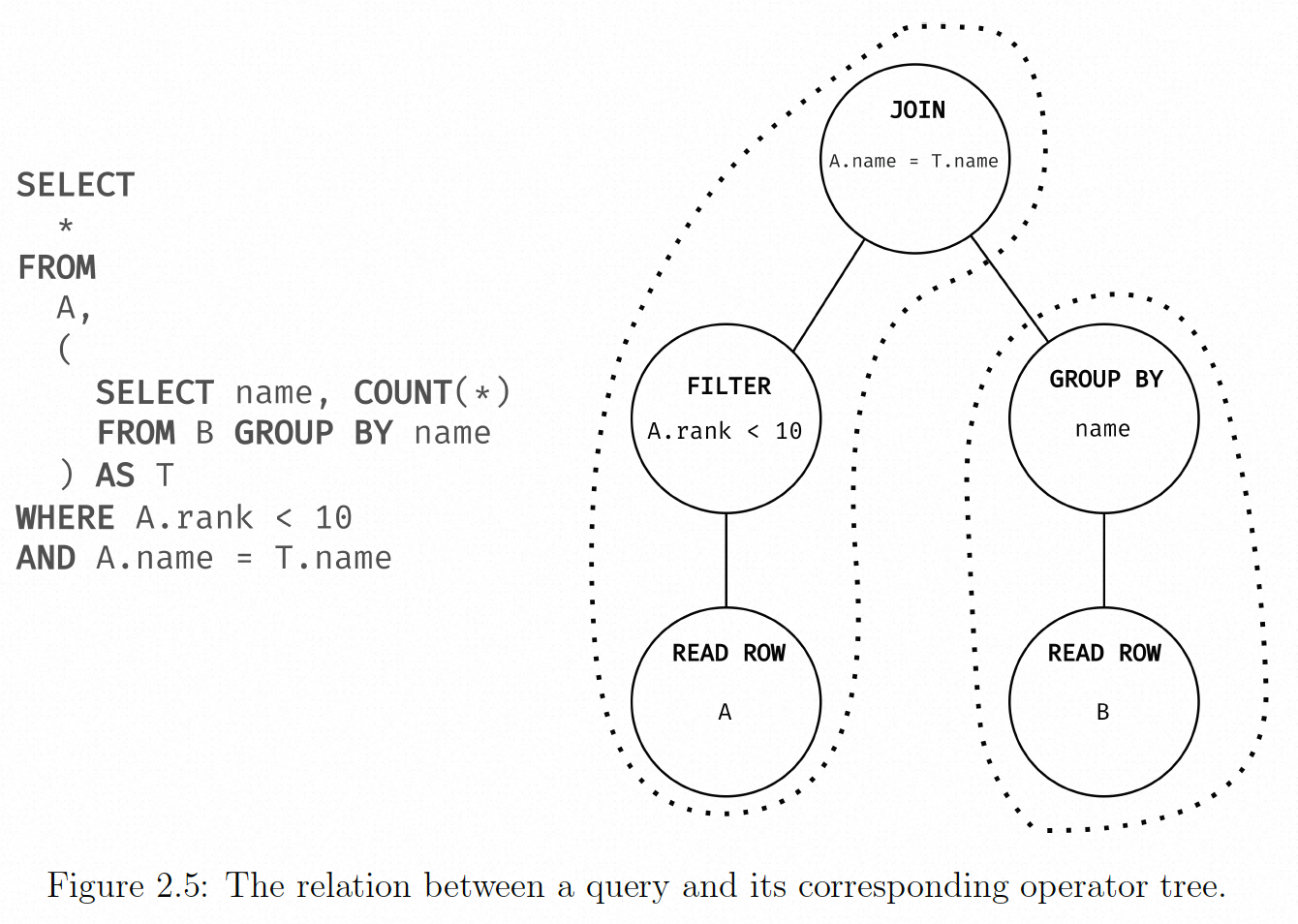
不是所有的算子都能一次处理一行数据; 这些算子被称为 pipeline breaker,需要等待子算子完成后才能开始处理数据,如 join,sort,group by。pipeline breaker 意味着许多查询,特别是复杂的查询,必须表示为多个pipeline。每个 pipeline 都形成一个类似临时表的实体,包含当前 pipeline 的结果数据,可以作为其他 pipeline 的输入数据。
图 2.5 显示了一个算子树,每个虚线包裹了一个 pipeline。
Volcano 模型的有点:扩展性好,使得加算子非常的简单,使用迭代接口。 在添加新算子无需考虑其他算子的执行。
Volcano 模型的最大缺点是大量重复 next() 的调用,占据大量的栈空间。程序内存空间中反复跳跃,降低 CPU 的分支预测率。
从 MySQL 8.0 以后,采用了 Volcano 迭代器模型。
5 论文的一些观点
很多传统数据库系统是在 IO 是瓶颈的时候而创建的。随着计算机内存的容量已经大大增加,数据库的很大一部分数据都跑在内存大小范围内,CPU 成为主要的一个瓶颈,这使得原有查询引擎的效率问题逐渐暴露出来。
许多系统仍采用 迭代器模型 来执行查询,简单来说由一个抽象操作接口组成,该接口支持针对不同类型的操作对虚函数的一系列重复调用来处理数据。有着大量的指令集合,这种模式加剧了 CPU 资源的利用不足。没有充分利用局部性,导致频繁的内存访问。
在现代 CPU 上,通过加强局部性原则和最小化指令,增加 cpu 友好型的执行优化,来提高内存系统的性能,是一种常见的思路。
因此,研究人员开始应用 编译器理论 到 数据库查询的原则和技术来应对这个日益增长的 CPU 瓶颈。这个主题的一些早期研究人员是 HIQUE 的作者,HIQUE 是一个为特定查询生成自定义代码的查询引擎。在他们的论文中,他们能够最小化函数调用的数量,减少指令的数量,提高缓存局部性, 并且在很大程度上优于基于解释的商业数据库系统。其他如 Hekaton,SingleStore,Spark等等都使用了这个技术。
[1] Compiling expressions in MySQL, Anders Hallem Iversen.
[2] Understanding MySQL internals.
[3] MySQL · 内核特性 · 8.0 新的火山模型执行器.
[5] MySQL源码解析之执行计划
[6] 庖丁解牛-MySQL查询优化器之JOIN ORDER